Architecture
Overview
Clustron DKV is a distributed, .NET-native key-value data engine designed for high-throughput, low-latency workloads in modern microservice environments.
The system is built around:
- Horizontal scalability
- Clear separation of control and data responsibilities
- Extensible internal engine components
- Predictable performance under load
- Instance-level isolation
Clustron DKV is evolving into a distributed data foundation rather than a simple cache.
Clustron DKV Architecture
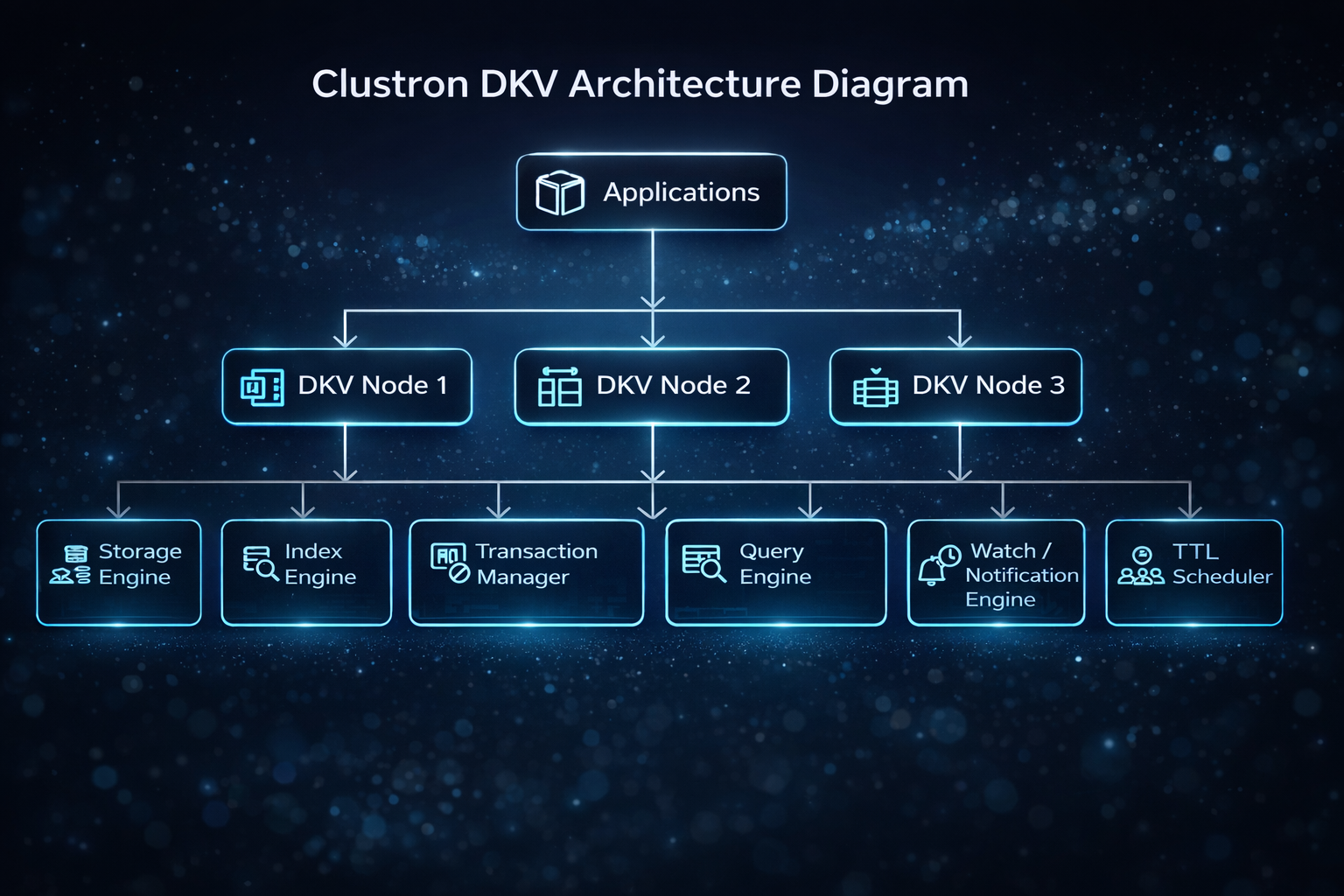
Each node operates as an independent process and participates in cluster coordination.
Control Plane vs Data Plane
Clustron DKV separates responsibilities into:
Data Plane
Responsible for:
- Key-value operations (Get, Put, Delete)
- Prefix queries
- Watch subscriptions
- TTL enforcement
- Index lookups
- Query execution
- Lease and locking primitives
- Counter operations
Data Plane is optimized for:
- Throughput
- Minimal GC pressure
- Efficient async networking
- Low overhead serialization
Control Plane
Responsible for:
- Store creation
- Instance lifecycle management
- Cluster configuration
- Port management
- Instance isolation
- Node startup and shutdown
- Configuration templates
Each DKV instance:
- Runs independently
- Has its own configuration
- Has isolated logging
- Can be deployed multiple times per host
This separation ensures operational clarity and horizontal scalability.
Node Architecture
Each Clustron DKV node contains the following core components:
1. Request Pipeline
Handles incoming client requests and routes them to appropriate engine components.
Designed for:
- Async I/O efficiency
- Minimal context switching
- Backpressure handling
- Structured error propagation
2. Segment Store
The core in-memory storage engine.
Responsibilities:
- Key partitioning
- Concurrent access management
- Data layout optimization
- Efficient memory usage
Segment-based partitioning allows scalable concurrency without global locking.
3. Index Manager
Provides:
- Equality indexing
- Range indexing
- Query acceleration
- Efficient lookup paths
Indexes are maintained alongside primary storage to avoid full scans for query operations.
4. Expiration Engine (TimeWheel-Based)
Clustron DKV uses a TimeWheel-inspired expiration model for TTL handling.
Benefits:
- O(1) expiration scheduling
- Predictable cleanup cost
- Reduced per-key timer overhead
- Avoids expensive scanning
This design improves performance under large TTL workloads.
5. Watch Engine
Supports prefix-based watch subscriptions.
Capabilities:
- Subscription to key prefixes
- Event delivery on mutations
- Snapshot + live event support
- Ordered event propagation
Designed for building reactive distributed systems.
6. Lease and Lock Engine
Provides distributed coordination primitives:
- Leases
- Lock acquisition
- Expiry-based coordination
- Safe release mechanisms
These primitives enable higher-level distributed workflows.
7. Counter Engine
Supports atomic distributed counters with:
- Increment
- Decrement
- Read
- TTL support
Designed for metrics, throttling, and coordination scenarios.
Cluster Model
Clustron DKV nodes form a logical cluster.
Key characteristics:
- Peer-to-peer coordination
- Node-aware routing
- Failure detection
- Rebalancing support (planned)
- Configurable priority-based reconnect behavior
Clients maintain:
- Priority server list
- Reconnect delay strategy
- Failover handling
Cluster design emphasizes consistency of operations within node ownership boundaries while maintaining horizontal scalability.
Multi-Instance Deployment
Clustron DKV supports multiple instances per machine.
Each instance:
- Runs on its own port
- Has isolated configuration
- Maintains independent logs
- Can be independently started/stopped
This enables:
- Resource partitioning
- Environment isolation
- Controlled multi-tenant deployments
Networking Model
The networking layer is designed for:
- High-throughput async operations
- Efficient socket usage
- Controlled connection lifecycles
- Graceful failover handling
The architecture avoids unnecessary abstraction layers to reduce overhead.
Scalability Philosophy
Clustron DKV is built around:
- Horizontal scale-out
- Stateless client design
- Predictable memory behavior
- Controlled coordination overhead
- Modular extensibility
The system is intentionally structured to allow future expansion into:
- Advanced query capabilities
- Observability integration
- Vector and similarity search
- Distributed job scheduling
- Additional distributed primitives
Observability (Planned Enhancements)
Future improvements include:
- Built-in metrics export
- Prometheus integration
- Per-instance performance tracking
- Cluster health reporting
- Operation tracing
Design Principles
Clustron DKV follows these principles:
- Performance-first
- Predictability over abstraction
- Extensibility without rewriting core engine
- Clear separation of responsibilities
- Operational clarity
- Practical distributed systems engineering
Current Status
Clustron DKV is in active development.
Core engine stabilization and documentation publication are ongoing.
Public open-source release of the core engine is planned for 2026 under a Business Source License.
What’s Next
👉 Continue to Store to understand how clusters are structured.